
Tra tutti i programmi OCR disponibili sul mercato, Tesseract è probabilmente il più famoso. Per tre motivi semplici: è open source, gratuito, e funziona molto bene. Tesseract nasce presso Hewlett-Packard nel 1985, e il suo sviluppo prosegue fino al 1994. Due anni più tardi il programma viene modificato leggermente per funzionare su Windows e nel 1998 buona parte del codice viene tradotto da C a C++. Dopo essere rimasto in un limbo per qualche anno, nel 2005 il suo codice sorgente viene rilasciato da HP, con la collaborazione dell’università del Nevada. Dall’anno successivo, Google decide di sponsorizzarne lo sviluppo. Grazie agli sforzi di Big G, che lo utilizza per il suo progetto Google Libri, per leggere i numeri civici delle abitazioni in Street View, ed altre applicazioni, Tesseract diventa il più potente strumento OCR a disposizione di ogni utente e di ogni programmatore. Manca, però, di un’interfaccia grafica ufficiale, e questo lo rende un po’ scomodo da usare per la maggior parte degli utenti. Nel tempo sono nate diverse interfacce grafiche non ufficiali, ma gImageReader è la più semplice e funzionale.
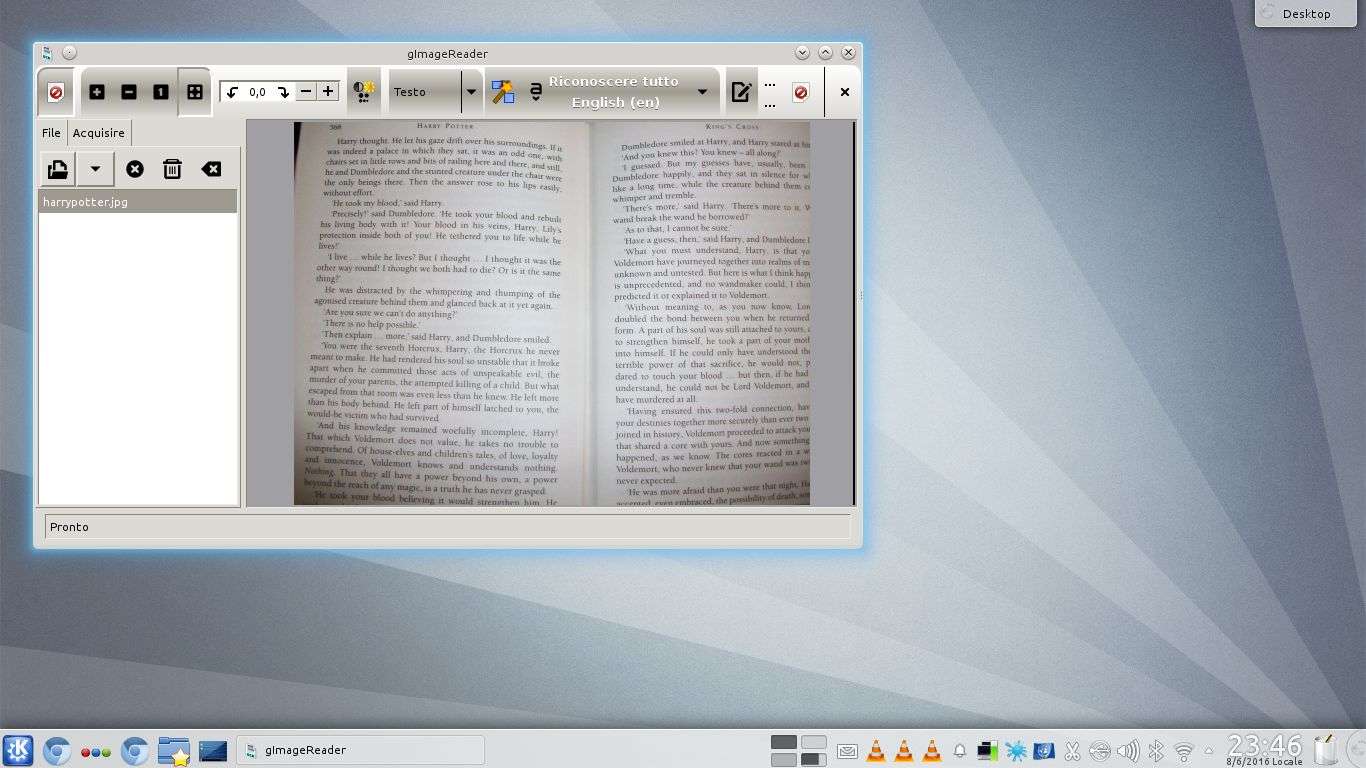
L’interfaccia di gImageReader è decisamente intuitiva: un semplice pulsante permette di selezionare delle immagini (scansioni o fotografie), e se ne possono aggiungere diverse. Se, ad esempio, stiamo scansionando un libro, possiamo aprire con gImageReader tutte le sue pagine. Semplici pulsanti permettono di ruotare la pagina anche solo di un decimo di grado per volta, al fine di posizionare il testo in modo perfettamente orizzontale per facilitare l’identificazione dei caratteri, e di correggere luminosità e contrasto per assicurarsi che questi siano leggibili.
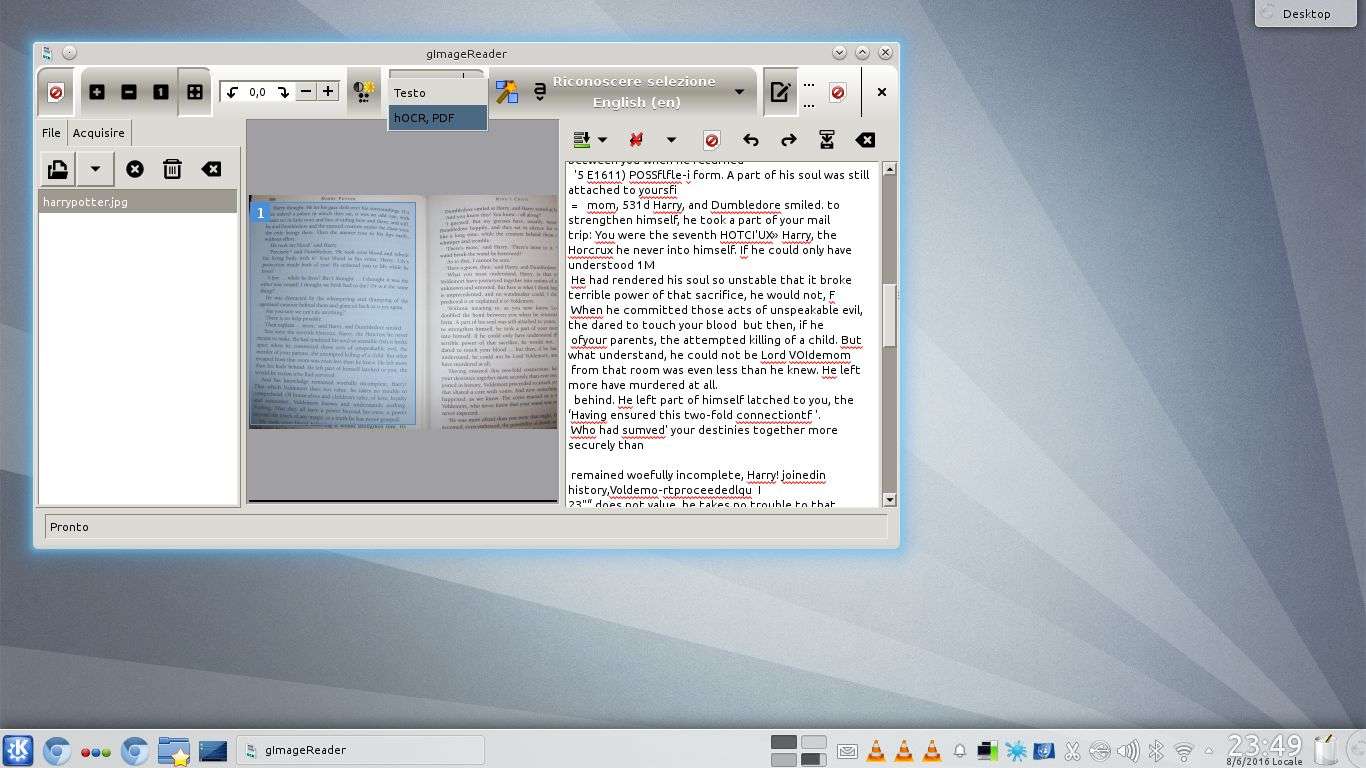
Affinché Tesseract possa comprendere il testo, è necessario indicargli la lingua in cui è stato scritto. gImageREader permette di farlo con un semplice menù a discesa. Si può poi selezionare una porzione dell’immagine (utile qualora siano state riprese due pagine del libro in un’unica foto) e procedere al riconoscimento del testo cliccando sull’apposito pulsante.
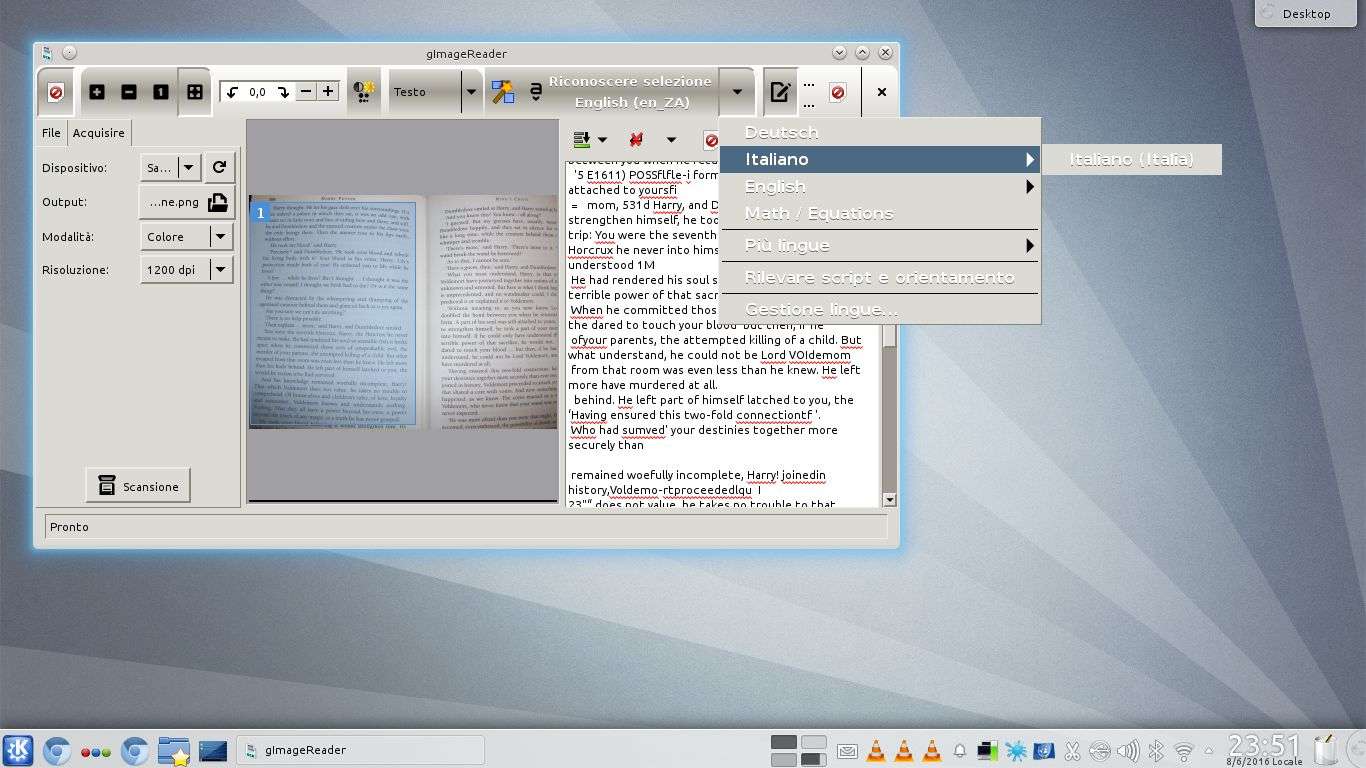
Il formato di output, ovvero il risultato finale, può essere scelto da un menù a tendina. Le opzioni sono due: possiamo ottenere il testo semplice, in una casella che apparirà appositamente subito dopo l’avvenuto riconoscimento dei caratteri, oppure generare un file in formato PDF. Il PDF che viene prodotto è un PDF hOCR, quindi ciò che si vede è l’immagine originale (la foto o la scansione che abbiamo fornito), ma con il testo nascosto in sovrimpressione all’immagine stessa. Di conseguenza, aprendo il PDF si vede l’immagine, ma utilizzando lo strumento di selezione testo del visualizzatore PDF è possibile selezionare e copiare il testo corrispondente alla porzione di immagine scelta. gImageReader dispone anche di una integrazione con SANE per utilizzare direttamente lo scanner: la scheda Acquisizione permette di scansionare diverse pagine e di aggiungerle all’elenco del carico di lavoro.