
Spesso capita di dover digitalizzare dei documenti con lo scanner. Il problema delle scansioni è che si tratta di immagini, quindi non si possono eseguire ricerche testuali all’interno del documento così creato. Ciò rende difficile la sua conservazione: in una cartella con decine di PDF scansionati l’unico modo per trovare quello che si sta cercando è controllare il contenuto di ciascuno di essi. La soluzione per leggere facilmente il contenuto dei PDF scansionati è applicarvi l’OCR.
Chiunque abbia uno scanner ed un PC GNU/Linux può produrre il PDF di un documento usando il programma img2pdf , ma questo conterrebbe le varie pagine sotto forma di immagini, non di testo. Il file può essere però trasformato in un PDF con OCR usando Tesseract e Ghostscript . Di seguito realizzeremo un semplice script per la shell di GNU/Linux che non solo estrapola il testo dal PDF, ma lo fonde con l’immagine in un nuovo PDF chiamato “searchable”, cioè “ricercabile”.
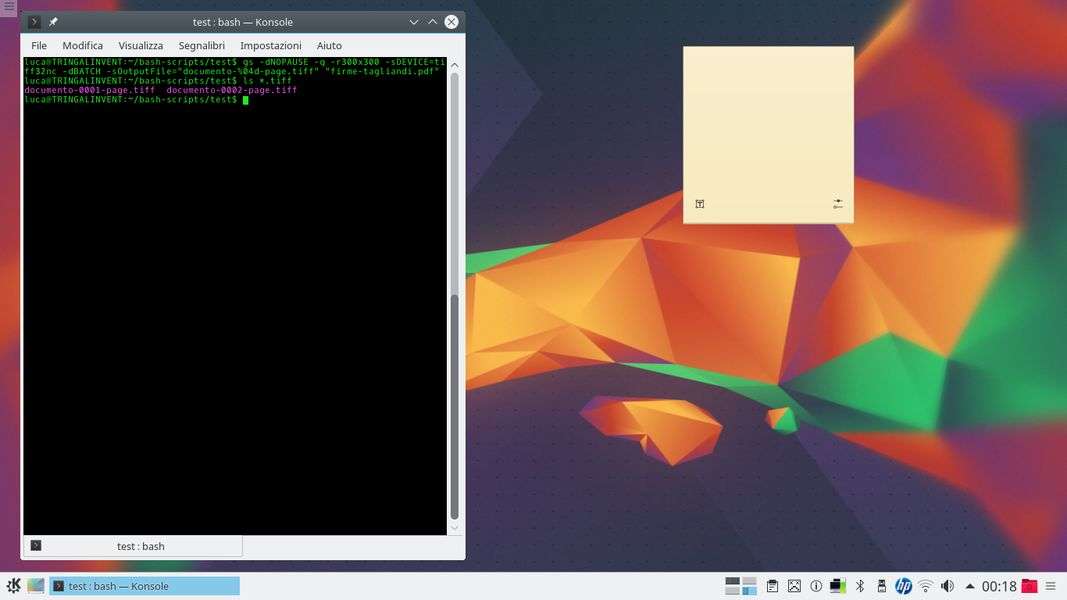
L’utility gs è in grado di manipolare i PDF, estraendo immagini da essi e creando nuovi PDF partendo da immagini, testi ed altri PDF. Per esempio, con un comando del tipo:
gs -dNOPAUSE -q -r300x300 -sDEVICE=tiff32nc -dBATCH -sOutputFile="documento-%04d-page.tiff" "documento.pdf"
Si produce un’immagine TIFF per ogni pagina del PDF. Le immagini vengono prodotte a 32 bit di profondità del colore e con una risoluzione di 300dpi (sia orizzontale che verticale).
A quel punto si può utilizzare un programma OCR come Tesseract per trasformare ogni immagine in un singolo PDF con OCR:
tesseract -l ita -psm 3 "immagine1.tiff" "immagine1-ocr" pdf
In alternativa, si può trasformare ogni immagine in PDF senza eseguire OCR utilizzando il comando:
img2pdf immagine1.tiff -o immagine1.pdf
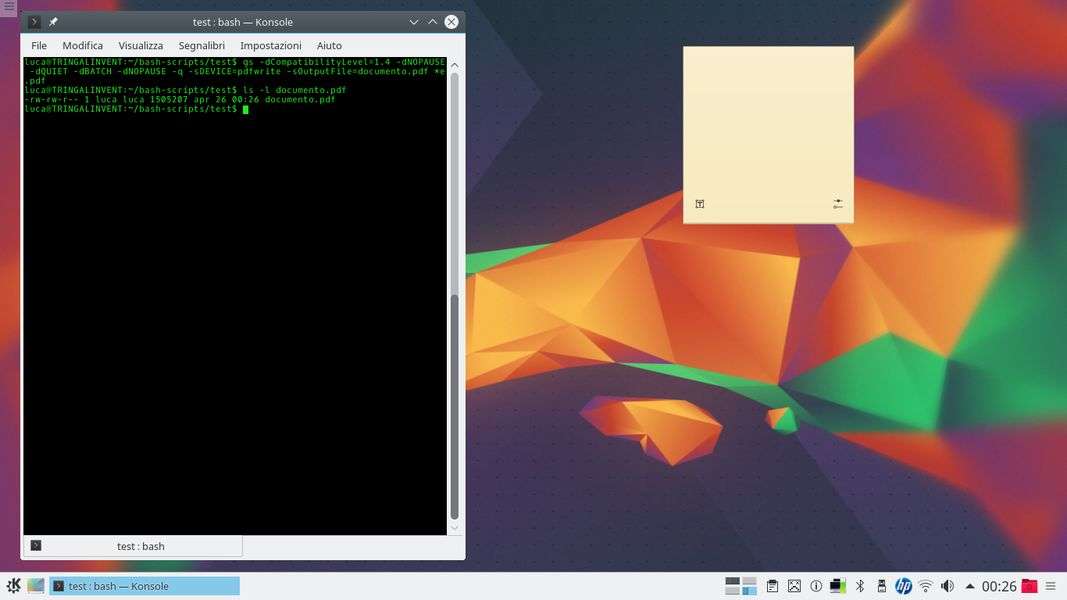
Poi il programma gs può essere utilizzato per unire più immagini in un unico PDF, ciascuna immagine come una pagina.
gs -dCompatibilityLevel=1.4 -dNOPAUSE -dQUIET -dBATCH -dNOPAUSE -q -sDEVICE=pdfwrite -sOutputFile=documento.pdf *.pdf
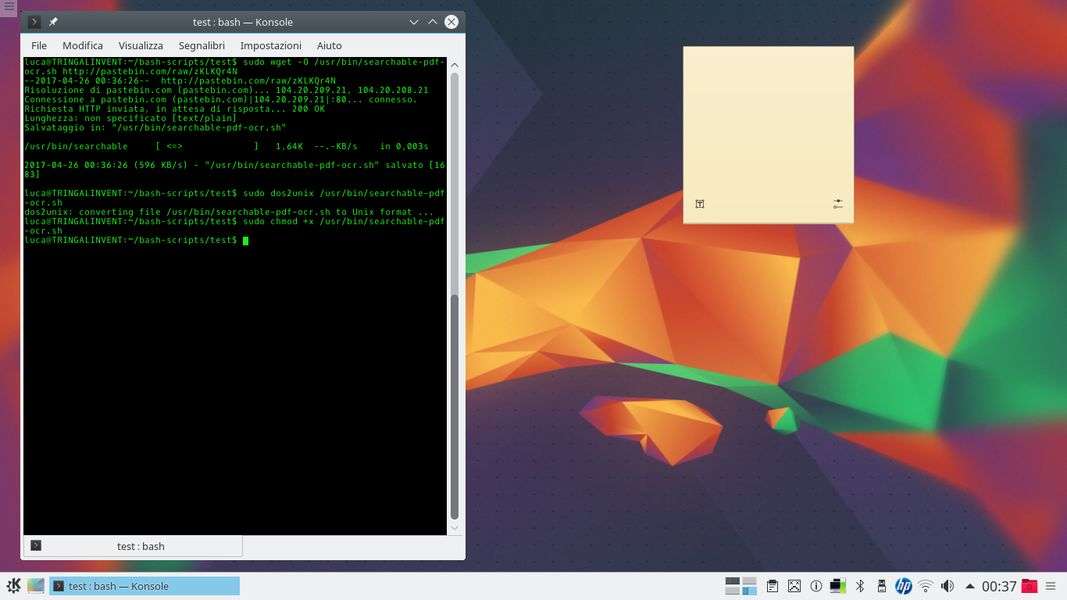
È proprio sfruttando queste due modalità di utilizzo di Ghostscript che abbiamo sviluppato un semplice script che trasforma un PDF costituito da immagini in un PDF con testo OCR sovrapposto alle immagini. Lo script separa tutte le pagine del PDF in singole immagini, e su ciascuna di esse esegue il programma Tesseract per ottenere il testo. Poi fonde di nuovo assieme il tutto. Lo script è pubblicato qui e si può installare con i seguenti comandi:
sudo wget -O /usr/bin/searchable-pdf-ocr.sh http://pastebin.com/raw/zKLKQr4N
sudo dos2unix /usr/bin/searchable-pdf-ocr.sh
sudo chmod +x /usr/bin/searchable-pdf-ocr.sh
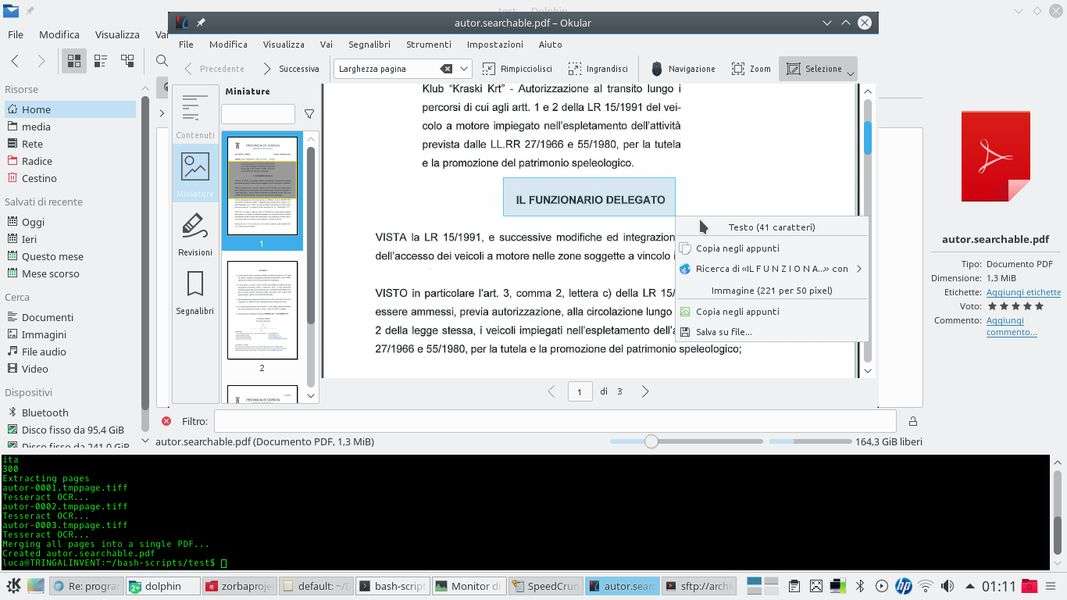
È poi possibile usare lo script dando semplicemente questo comando:
searchable-pdf-ocr.sh originalfile.pdf ita 300
Dove ovviamente il primo argomento è il PDF su cui si vuole eseguire l’OCR, il secondo argomento è la lingua (italiano) e il terzo la risoluzione desiderata per le immagini (300 dpi).