

Gemini 3.1 Flash-Lite è il modello più veloce ed efficiente della famiglia. E l’articolo potrebbe concludersi qui. È esattamente quanto ci troviamo a ripetere ogni volta che ne viene presentato uno, indipendentemente dal fatto che ad addestrarlo sia stata Google o un’altra realtà dell’ambito AI. Vediamo però di cosa è capace.
Gemini 3.1 Flash-Lite: velocità e flessibilità
Introduce vantaggi anche per quanto riguarda i costi di gestione: 0,25 dollari per milione di input token e 1,50 dollari per milione di output token. I benchmark lo promuovono nel testa a testa con il predecessore 2.5 Flash, documentando un’accelerazione pari a 2,5 volte nella generazione del primo output, senza compromettere la qualità e l’accuratezza del risultato.
Oggi presentiamo Gemini 3.1 Flash-Lite, il nostro modello della serie Gemini 3 più veloce ed economico. Progettato per carichi di lavoro di sviluppo ad alto volume su larga scala, 3.1 Flash-Lite offre un’elevata qualità per il suo prezzo e la sua fascia.
Il grafico qui sotto mostra la velocità di output (una colonna più alta rappresenta un risultato migliore). Gemini 3.1 Flash-Lite è messo a confronto con altri modelli attraverso test eseguiti con modalità di ragionamento differenti.
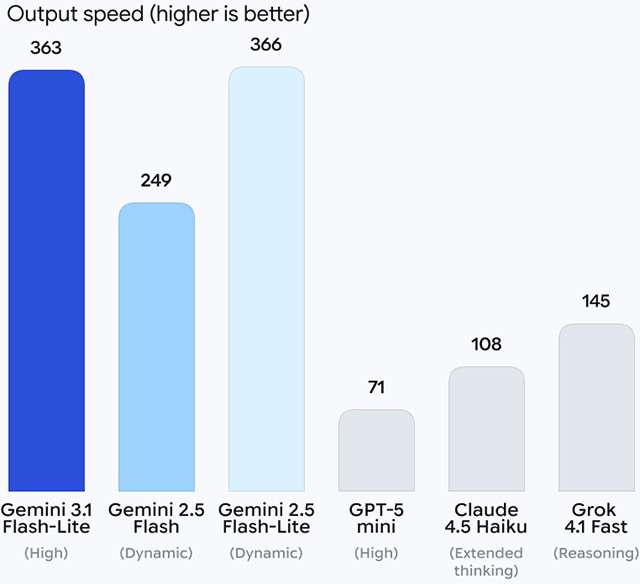
Qui sotto una demo che lo mostra in azione, al fianco di Gemini 2.5 Flash. La rapidità sembra effettivamente essere il suo punto di forza.
Rapidità a parte, un altro vantaggio sottolineato dal gruppo di Mountain View è quello relativo a controllo e flessibilità. Sono qualità essenziali per gli addetti ai lavori. Può gestire carichi complessi e attività su larga scala selezionando il livello di pensiero più adatto in base a ogni situazione, passando quando necessario a un ragionamento più approfondito.
L’accesso al nuovo modello Gemini 3.1 Flash-Lite al momento è consentito solo in anteprima agli sviluppatori attraverso l’API di Gemini in Google AI Studio e alle realtà enterprise tramite Vertex AI. Alcune società come Latitude, Cartwheel e Whering lo stanno già mettendo alla prova.
Ti potrebbe interessare





4 mar 2026