

Che sia Alexa, che sia Google Translate o che sia un traduttore istantaneo vocale, in ogni caso il meccanismo di traduzione si basa su dinamiche che attingono alle specifiche delle lingue scritte. Tutto si basa sulla scrittura, insomma, che diviene la base dell’analisi e degli output di questi servizi. Sebbene non sempre la cosa sia perfettamente nota, infatti, c’è un ampio numero di lingue nel mondo che non godono di alcuna versione scritta e che ad oggi si tramandano esclusivamente in forma parlata. Meta ha annunciato che, grazie ai benefici dell’Intelligenza Artificiale, ora anche queste lingue potranno essere tradotte e trovare quindi una corrispondenza più semplice con le altre lingue di tutto il mondo. Le lingue non scritte, insomma, potranno essere trattate al pari di quelle scritte approfittando di nuovi modelli di apprendimento che nutriranno gli algoritmi di Menlo Park.
Meta, l’IA parlerà in tutte le lingue del mondo
Si tratta di un passo avanti di grande importanza per la conservazione della ricchezza che le lingue rivestono per le culture di tutto il mondo. “Più del 40% delle oltre 7000 lingue attualmente in uso sono principalmente orali“, spiega Meta, “e non hanno una forma scritta standard o un sistema di scrittura adottato su larga scala“. Poter entrare in contatto più vivo e diretto con queste comunità è una missione sulla quale si investe da tempo e solo ora, grazie all’IA, sarà possibile raggiungere l’obiettivo. Il primo vero problema da superare è quello della raccolta dati, perché soltanto nutrendo l’IA con un massiccio numero di informazioni è possibile approfittare dei benefici del machine learning. Per Meta, però, la prova è ormai superata e lo dimostra il caso della lingua Hokkien:
Raccogliere dati sufficienti è stato un ostacolo importate che ci si è presentato durante la creazione del sistema di traduzione per l’hokkien. È noto che si tratta di una lingua povera di risorse: ciò significa che non esiste un’ampia gamma di dati disponibili per allenare il sistema, se la paragoniamo allo spagnolo o all’inglese, per esempio. Inoltre, esistono pochi traduttori umani dall’inglese all’hokkien e ciò complica la raccolta e l’annotazione dei dati per l’allenamento del modello. Abbiamo sfruttato il mandarino come lingua intermedia per creare delle pseudo etichette, per prima cosa abbiamo tradotto un contenuto vocale in inglese (o hokkien) in un testo in mandarino e poi lo abbiamo tradotto in hokkien (o inglese) e aggiunto ai dati per l’allenamento del modello. Questo metodo ha migliorato enormemente le prestazioni del modello sfruttando i dati di lingue simili con più risorse disponibili.
Per raggiungere l’obiettivo, Meta spiega di aver dovuto disegnare un approccio completamente nuovo:
Abbiamo utilizzato la traduzione speech-to-unit (S2UT) per tradurre il contenuto vocale di partenza in una sequenza di unità acustiche direttamente nel percorso precedentemente lanciato da Meta. Poi abbiamo generato forme d’onda partendo da quelle stesse unità. Inoltre, abbiamo adottato Unity per un meccanismo di decodifica a 2 fattori, dove il primo decoder genera un testo in una lingua correlata (mandarino) e il secondo decoder crea le unità.
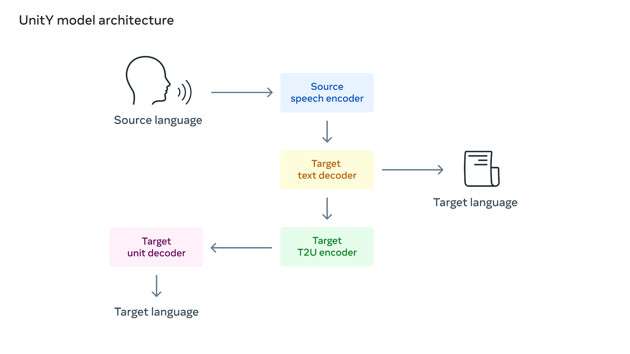
Ancor più importante, è il modo in cui Meta renderà disponibili queste informazioni alla comunità scientifica: “Renderemo questo dataset per il benchmark open source per incoraggiare altri ricercatori a lavorare alla traduzione orale dell’hokkien e fare insieme ulteriori progressi nel campo“.
Quello che l’IA promette di fare, insomma, è una nuova Torre di Babele nella quale ognuno parlerà la propria lingua, ma tutti potranno mutuamente comprendersi. Non si danno indicazioni temporali, ma in quell’orizzonte che il gruppo chiama “futuro”, “tutte le lingue, scritte o non scritte, non saranno più un ostacolo alla comprensione reciproca“.
Ti potrebbe interessare





19 ott 2022