
Le varie distribuzioni GNU/Linux, in particolar modo quelle dedicate al “grande pubblico”, giungono agli utenti con kernel in grado di soddisfare le esigenze di una variegata platea. Si pensi, ad esempio, al numero e tipo di periferiche che un utente desktop può utilizzare: molto probabilmente saranno diverse da quelle richieste da un altro utente GNU/Linux in un’altra parte del mondo. Si tratta di kernel nei quali vengono abilitate un’infinità di opzioni che faranno parte o dell’immagine statica del kernel – ovvero del blocco “monolitico” caricato in fase di avvio – o come moduli caricabili a run-time e presenti in /lib/modules/”uname -r” . Le funzioni abilitate, così come un certo numero di driver caricati o da poter caricare con il comando modprobe nome_modulo , in buona percentuale dei casi risulteranno totalmente inutili, ancor più se pensiamo a un server per il quale non è necessario che il sistema risulti user-friendly (amichevole); ciò che conta in questi casi è la sicurezza e la stabilità del sistema, sia lato kernel sia per quanto riguarda il software installato.
Sicurezza e kernel
Se vogliamo raggiungere un buon grado di sicurezza, a maggior ragione se la macchina è un server, occorre sapersi costruire un kernel ad-hoc (specifico) attivando solo ciò che realmente occorre e sposando il motto “tutto quello che non c’è, non si può rompere”. Che senso avrebbe attivare il supporto audio su un server che non ne farà mai uso? O ancora il supporto per i joystick o per un dato file system non in uso o periferiche SCSI non utilizzate? Per ottenere un risultato mirato occorre saper scaricare, applicare eventuali patch, configurare, (ri)compilare e installare un kernel partendo dai sorgenti. Operazioni, queste, che possono incutere un po’ di timore, ma dal punto di vista pratico si risolvono nel lanciare un certo numero di comandi (che in questa sede esulano dal contesto). Molto più difficile, invece, è il tuning delle singole voci del kernel, di quello che ci occorre realmente, poiché le opzioni selezionabili hanno raggiunto ormai le svariate centinaia. In questo articolo ci concentreremo su Yama , opzione presente nella sezione Security options del kernel.
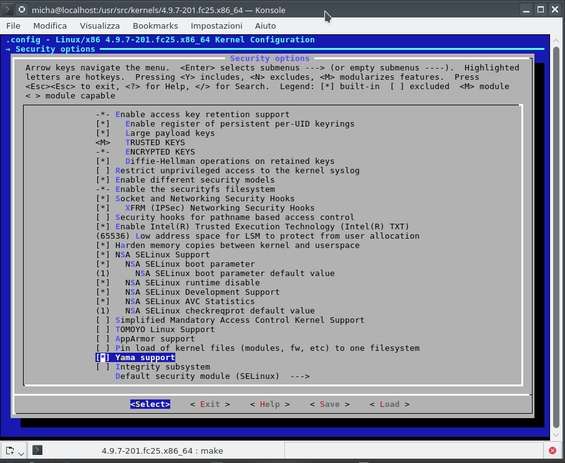
Sezione Security options dal comando make menuconfig
Dall’help in linea, la descrizione riporta, traducendo in Italiano le parti di interesse: “Questa opzione seleziona l’opzione Yama la quale estende il supporto DAC dei sistemi GNU/Linux (…). Attualmente la funzione disponibile è la restrizione della visibilità della syscall ptrace (…). Analogamente alle altre funzionalità, anche le funzioni di Yama sono accessibili via LSM”.
Per capire cosa fa e come funziona questa opzione del kernel, nonché qual è lo scopo che si prefigge, sono 3 le parti sulle quali occorre concentrare l’attenzione:
1. Estende il supporto DAC con ulteriori impostazioni di sicurezza a livello di sistema;
2. L’opzione di sicurezza va ad affiancare gli altri moduli grazie a LSM ;
3. Disabilita o limita la visibilità della chiamata di sistema ptrace .
Cos’è il DAC?
Acronimo di Discretional Access Control , il DAC è nato e si è sviluppato con i sistemi UNIX e adottato in toto dai sistemi GNU/Linux. Poiché nei sistemi UNIX/UNIX-like tutto è un file, ecco che il DAC è definito da un insieme di autorizzazioni (permessi) attraverso le quali è possibile effettuare il controllo dell’accesso ai file ovvero la capacità di assegnare, ad opera dell’amministratore di sistema e in limitata parte anche dall’utente “normale”, i permessi di esecuzione, lettura e/o scrittura. Il comando ls -l ( man ls ) impartito nella nostra home utente elencherà file e directory in essa presenti. Soffermiamo la nostra attenzione sulla prima colonna che è possibile dividere in 4 sezioni.
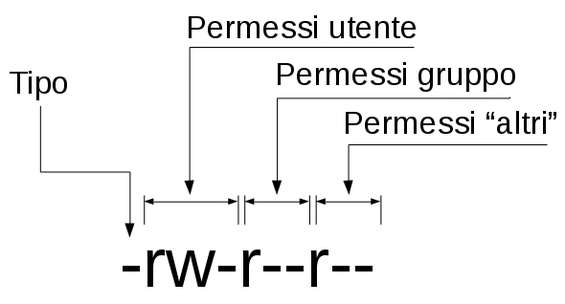
Le 4 parti della prima colonna dell’output del comando ls
La prima sezione riporta il tipo di file: il carattere – indica un file normale, la d una directory, c un dispositivo a caratteri, b un dispositivo a blocchi e l un collegamento simbolico. La parte restante contiene le autorizzazioni, raggruppate in 3 sezioni: l’utente proprietario del file, il gruppo di appartenenza di cui possono farne parte uno o più utenti, e tutti gli altri (ovvero utenti che non sono né il proprietario del file e non fanno parte del suo gruppo di appartenenza). In ognuna delle 3 sezioni può apparire la lettera r a indicare che il file è leggibile, w il file è scrivibile, x il file è eseguibile e – a indicare che il dato permesso non è stato impostato.
Nell’esempio in figura abbiamo un file regolare il cui utente proprietario può leggere e scrivere (modificare) il file, gli utenti appartenenti al gruppo possono soltanto leggerlo così come tutti gli altri. Ogni permesso corrisponde a uno specifico bit di una variabile che viene mantenuta in una struttura nota con il nome di inode : assegnare/modificare un permesso significa modificare il bit specifico presente nella struttura.
Permessi di file e directory possono essere modificati con il comando chmod ( man chmod ), per cambiare proprietario e gruppo si usano rispettivamente chown ( man chown ) e chgrp ( man chgrp ) infine per gli attributi speciali, funzione anche del file system in uso, si utilizza chattr ( man chattr ). Alcuni file eseguibili possono avere una s al posto della x a indicare che è attivo il bit setuid (Set User ID). Questo significa che quando lanciamo quel programma esso verrà eseguito con i privilegi dell’utente di appartenenza.
In tale ottica ricordiamo che il kernel assegna degli identificatori unici ad ogni utente, oltre a UID (User ID) e GID (Group ID) vengono utilizzate altre due coppie di identificatori: gli ID effettivi EUID (Effective User ID) e EGID (Effective Group ID) e gli ID reali RUID (Real User ID) e RGID (Real Group ID).
Quando viene eseguito un programma con bit suid attivato, l’utente che lo ha lanciato assumerà l’EUID (o l’EGID se è attivo il sgid , Set Group ID) del proprietario del file, ma il kernel è sempre in grado di identificare chi ha fatto la richiesta poiché i valori RUID e RGID non cambiano e identificano univocamente l’utente.
Al valore degli identificatori possiamo risalire utilizzando il comando id ( man id ). Ma perché questo apparente complicato meccanismo sul controllo degli accessi? Poiché GNU/Linux è un sistema multiutente non si può escludere che più utenti possano lavorare, anche in contemporanea, sulla macchina. Grazie al sistema DAC l’utente X, in funzione dei permessi impostati, non può modificare i file dell’utente Y. In sostanza, non si possono arrecare danni ad altri utenti e, soprattutto, al sistema nel suo complesso. Osserviamo però come nel modello DAC la decisione sulla sicurezza sia a discrezione dell’utente ed è basata solo sull’identità sulla proprietà dell’oggetto, ad esempio un file o una cartella. Non c’è nessun’altra protezione.
La struttura LSM
La sicurezza in informatica è quella disciplina da adottare al fine di proteggere la propria organizzazione/azienda attuando apposite misure atte a contrastare eventi accidentali o intenzionali che possano produrre una compromissione parziale o totale dei dati e/o del sistema. Così definita è assolutamente generica e può spaziare dalla sicurezza fisica della macchina alla sua continuità di servizio, dalla privacy all’integrità dei dati, laddove ogni singolo argomento porta con sé un importante numero di possibili soluzioni. Ad esempio, solo per la prima voce: alimentatori ridondanti, adozione del RAID e possibile scelta del clustering. Allora rendere “sicuro” un sistema è un percorso lungo e complicato poiché coinvolge diversi aspetti dello scibile informatico. Quanto detto vale anche a livello software laddove l’introduzione continua di nuove caratteristiche, che nella pratica implica l’aggiunta di nuove righe di codice, nonché l’uso più massiccio, rispetto al recente passato, di un certo tipo di software (si pensi ai vari CMS come WordPress e Joomla) ad opera di un numero sempre più crescente di persone, porta a un problema cronico di sicurezza anche per sistemi GNU/Linux, come dimostra il flusso continuo di vulnerabilità di sicurezza. Rimanendo nella zona di competenza del kernel vediamo qual è la misura adottata per permettere l’inserimento dei diversi metodi di protezione. Ricerche sulla sicurezza hanno prodotto diversi metodi sul controllo degli accessi che vanno sicuramente nella direzione di una maggiore sicurezza offerta al sistema, tuttavia non c’è consenso unanime su quale possa essere la soluzione migliore. Non solo, anche ipotizzando di implementare tutti i vari meccanismi di controllo occorre, come da esplicita richiesta di Linus Torvalds, che:
– non si faccia alcun favoritismo a questa o quella società di sicurezza;
– l’interfaccia deve essere concettualmente semplice, poco invasiva ed efficiente;
– possa essere facilmente integrato senza dover stravolgere la struttura del kernel e il “classico” controllo DAC dovrà continuare ad essere verificato.
Per questi motivi, a partire dalla versione 2.6 del kernel venne introdotto il framework LSM (Linux Security Modules).
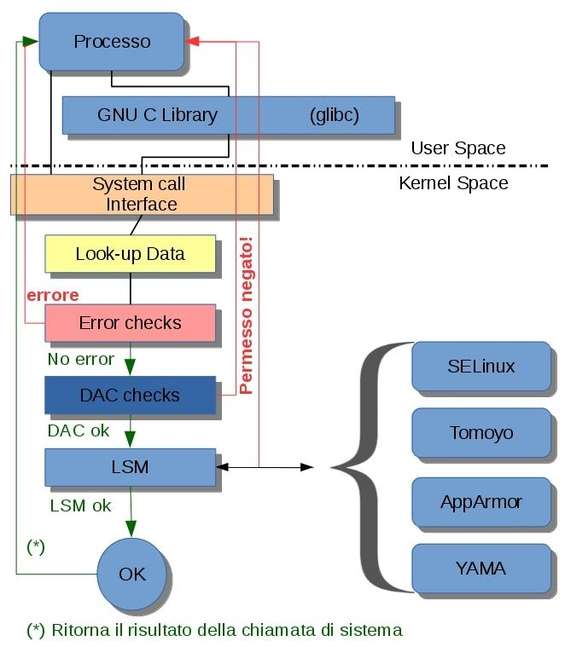
Controlli attuati dal kernel (DAC+LSM): principio di funzionamento
Come visibile in figura, LSM offre un’interfaccia attraverso la quale è possibile implementare nuove politiche di sicurezza lato kernel e utilizzando gli specifici tool di controllo e configurazione in user space (lato utente).
La filosofia ad alto livello, senza entrare nei dettagli implementativi a basso livello (livello di codice) che esulano da questo contesto, vede un processo utente eseguire, previo uso di specifiche librerie, la chiamata di sistema. A questo livello, dall’altra parte dell’interfaccia in kernel space, i dati user space, ad esempio un nome di percorso, devono essere ancora tradotti nell’oggetto kernel che li rappresenta come ad esempio un inode, pertanto viene processata prima questa richiesta. A questo punto, dopo aver eseguito un controllo degli errori, se non viene riscontrato alcun problema la palla passa al DAC. Se l’utente che ha fatto la richiesta non ha i giusti permessi viene negata l’azione (che potrebbe essere la lettura di un file) altrimenti viene concesso il permesso, ma prima di intraprendere l’azione richiesta viene effettuato un altro controllo attraverso l’interfaccia LSM, che chiede al modulo in uso se la richiesta, in base alla configurazione, risulti lecita o meno. Solo a questo punto si ha la risposta definitiva. In buona sostanza, una richiesta può superare il DAC ma non è detto che superi la politica di sicurezza attivata via LSM; ma se non supera il DAC a LSM non ci arriva nemmeno.
Cos’è una syscall
In GNU/Linux l’accesso alle risorse di sistema non avviene in modo diretto, vengono utilizzate apposite interfacce che agiscono tra due livelli: in alto chi fa la richiesta e in basso l’interazione con l’hardware, sia essa la CPU piuttosto che i dischi o le varie schede. Si viene così a creare un modello stratificato che aumenta la sicurezza perché il controllo a una data richiesta, ad opera di un programma lato utente, e che quindi gira in user space, deve gioco forza passare attraverso il kernel, che potrà certificarne la regolarità o meno. Una stratificazione di questo tipo assicura anche una buona portabilità: in questo modo si possono eseguire le medesime applicazioni anche su kernel di versioni differenti, a patto che le interfacce rimangano le stesse. Sul bordo dell’interfaccia possiamo così definire due attori: le API (Application Programming Interface) e le system call (“syscall” o “chiamate di sistema”) ovvero le entry point che il programmatore ha a disposizione per comunicare con il kernel. Al livello più alto abbiamo le API, che definiscono delle funzioni attraverso le quali è possibile richiedere e ottenere un servizio. Nei sistemi UNIX, ogni system call corrisponde a una funzione di libreria C: il programmatore chiama la funzione utilizzando la sequenza di chiamata standard del C, e la funzione, in maniera trasparente all’utente, invoca il servizio del sistema operativo nel modo più opportuno. Non tutte le funzioni associate alle API, però, invocano una chiamata di sistema: ad esempio, la funzione C printf() può invocare la system call write() ma la funzione C strcpy() per la copia delle stringhe o la funzione atoi() per la conversione da ASCII a intero, non ne coinvolgono alcuna.
Non è necessario comprendere i meccanismi a basso livello che scaturiscono da una chiamata di sistema: nella figura seguente vediamo la dinamica di principio.
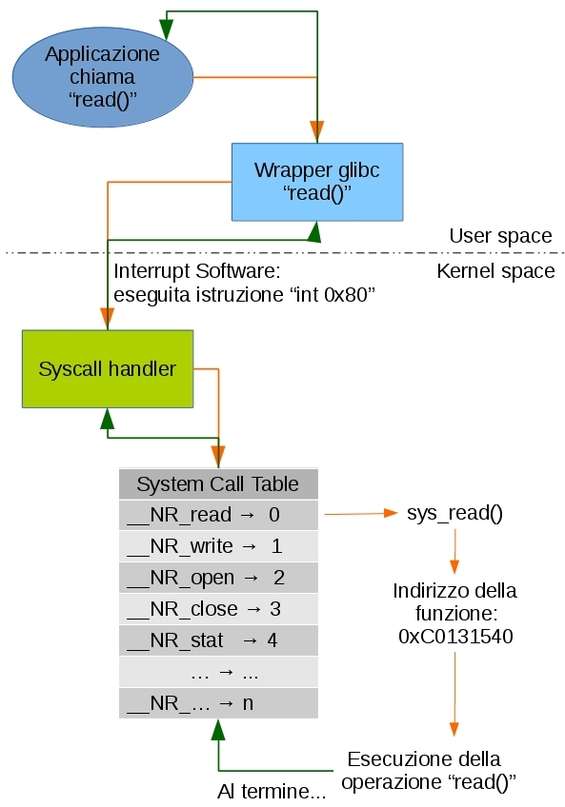
Invocazione di una chiamata di sistema
L’applicazione utente richiede, ad esempio, la lettura di un file previo uso della funzione read() della libreria C per la chiamata in user space. A questo punto la libreria C funge da tramite per l’omonima chiamata di sistema read() e un interrupt software (istruzione int 0x80 ) viene generato cambiando la modalità kernel e passando il controllo al gestore delle syscall ( syscall handler ). Poiché ad ogni chiamata di sistema è associato un ID, il syscall handler, previo uso della chiamata sys_call_table , accede alla omonima struttura che contiene l’indirizzo delle funzione kernel che stiamo richiedendo. Al ritorno dalla chiamata di sistema l’esecuzione riprende nella libreria C che ritorna all’applicazione utente. In /usr/include/asm/unistd_64.h vi sono gli identificativi di tutte le syscall implementate nel kernel a cui corrisponde una specifica macro di nome __NR_nome_syscall . Il syscall handler è così in grado di identificare la funzione kernel da richiamare i cui nomi iniziano tutti con il prefisso sys_ , ad esempio sys_read per la lettura di un file. Ad esempio, la chiamata ptrace ha identificativo 101. Una chiamata al kernel porta all’esecuzione di un’istruzione privilegiata. Il codice in kernel space, poiché viene lanciato in kernel mode , verrà eseguito nella modalità Ring 0 livello nel quale si ha accesso a tutte le istruzioni macchina. Nell’architettura x86 vengono definiti 4 livelli gerarchici di protezione o anelli di protezione: Ring 0 detto kernel mode, Ring 1 e Ring 2 ad uso dei servizi del sistema operativo: ad esempio i device driver in Ring 1 e Ring2, hypervisor di sistemi virtuali in Ring 0 e Ring -1, quest’ultimo creato ad-hoc affinché un sistema operativo guest sia grado di eseguire le operazioni a Ring 0 nativamente senza influenzare gli altri guest o il sistema host che lo ospita. Il livello con minori privilegi è Ring 3 dove vengono eseguite le usuali applicazioni che hanno accesso solo ad un sottoinsieme molto limitato delle istruzioni del processore.
Kernel space vs User space: una differenza vitale
A questo punto occorre fare una precisazione. In un sistema GNU/Linux la memoria viene divisa in due distinte aree: lo spazio utente ( user space ) e lo spazio kernel ( kernel space ). User space è quella parte di memoria dove vivono i processi utente: il ruolo del kernel è di gestirne le applicazioni (processi) ivi presenti controllando che un processo non invada celle di memoria che non gli competono nel qual caso venga “assassinato”; di fatto viene inviato un segnale SIGSEGV generando un errore di segmentazione ( Segment Violation ) a indicare un accesso illegale alla memoria.
Il kernel space, invece, indica quella parte di memoria dove il codice del kernel viene memorizzato ed eseguito dal processore. Per quanto detto, i processi in user space hanno solo una parte limitata di memoria e se tentano di occupare memoria non di loro pertinenza vengono chiusi immediatamente.
Il kernel, invece, ha accesso a tutta la memoria. Processi che girano in user space non hanno accesso alla memoria in kernel space, ma possono accedervi in minima parte solo attraverso un’interfaccia messa a disposizione dal kernel attraverso le syscall. Ricordiamo, infine, che anche i processi dell’utente root (amministratore) girano in user space: non si confondano i due concetti!
Finalmente Yama!
Ora che abbiamo una panoramica di tutti gli attori in gioco dobbiamo tirare solo le somme e il testo sulla descrizione di Yama appare sicuramente più comprensibile: Yama estende il modello DAC introducendo un ulteriore livello di controllo, attraverso il framework LSM, sulla chiamata di sistema ptrace() .
Al momento di scrivere, il controllo su ptrace() è l’unica funzione disponibile, ma non si può escludere che di nuove verranno implementate in futuro visti i tempi necessari. Infatti, nel caso specifico, la prima proposta avvenne nel giugno 2010 come patch al kernel ad opera di Kees Cook dell’Ubuntu Security Team, ma solo nel maggio 2012 è stata ufficializzata con il rilascio del kernel 3.4.0.
Concettualmente la funzione è semplice: mentre le altre soluzioni che si appoggiano a LSM, come AppArmor , Tomoyo e SELinux , fanno da supplemento al DAC implementando un controllo di accesso vincolato ( MAC – Mandatory Access Control), nel caso di Yama la funzione è limitare la visibilità alla syscall ptrace (Process Trace) balzata agli onori della cronaca per un problema legato all’installazione dell’ambiente di sviluppo videoludico Unity 5 . Il framework viene rilasciato solo per sistemi Microsoft Windows e Mac OS, ma produce giochi che possono girare su svariati sistemi operativi compresi Android e GNU/Linux, ma è pienamente supportato da WINE . Chi tentava l’installazione falliva miseramente se una specifica flag era impostata a 1 e il cui valore può essere determinato con i comandi sysctl kernel.yama.ptrace_scope o cat /proc/sys/kernel/yama/ptrace_scope laddove il supporto a Yama sia stato abilitato nel kernel. Infatti alcune distribuzioni, come OpenSUSE, lasciano disabilitata questa voce; altre, come Fedora, la abilitano di default. Ma perché tutto questo “rumore” attorno ad una chiamata di sistema?
Tracciamento dei processi
Quando si crea un programma, anche il più banale, chi lo sviluppa dopo aver scritto le usuali righe di codice passa – se utilizza il linguaggio C – alla fase di compilazione che termina con un file eseguibile. Tale eseguibile diventa un processo nel momento in cui viene mandato in esecuzione. Non è sufficiente, però, creare l’eseguibile e lanciarlo. Esiste una fase successiva, tanto più difficile quanto più complesso è il programma, nota con il nome di “debugging”: una diagnostica sul programma (quindi sul processo) lanciato ad opera di un altro programma (quindi di un altro processo) con lo scopo di trovare errori che non inficiano il funzionamento del programma in sé, quanto la sicurezza dello stesso sul sistema. Poiché la comunicazione tra processi ( IPC , Inter-Process Communication) avviene per mezzo delle chiamate di sistema, ecco che il “back-end” di un debugger come gdb è proprio una chiamata di sistema e nello specifico è proprio la chiamata ptrace() .
Dov’è la pericolosità della syscall ptrace()? Per visualizzare il problema dobbiamo vedere come opera: ptrace() fornisce un mezzo ad un processo, che chiameremo tracciante , attraverso il quale può osservare e controllare l’esecuzione di un altro processo, che chiameremo tracciato , del quale può esaminarne e cambiarne anche la memoria e i registri. Un comportamento decisamente intrusivo poiché un singolo utente può esaminare la memoria e lo stato di esecuzione di uno dei vari processi. Ad esempio, se un programma (a causa di un bug ancora non corretto) è stato compromesso, sarebbe possibile per un utente malintenzionato collegarsi ad altri processi in esecuzione, il browser Firefox o una sessione SSH, estraendo così alcune credenziali; e nessuno può fermarlo perché poi potrebbe passare ad esaminare un altro processo per rubare altre credenziali e così via. Il problema non era solo teorico poiché diversi attacchi già esistevano quando la patch è stata proposta e sono tutt’oggi reali se si permette a ptrace() di operare “indisturbata”.
Per tirare le conclusioni, poiché ptrace() abilita un processo a controllarne l’esecuzione di un altro, l’uso pratico dovrebbe essere riservato a sviluppatori software (per il debugging) e più raramente a qualche amministratore di sistema, in tutti gli altri casi è meglio disabilitarla o quanto meno “depotenziarla”. Nel paragrafo precedente abbiamo visto come valutarne il valore che può essere compreso tra 0 e 3, più precisamente:
– 0 , tipico modo di lavorare di ptrace: tutti i processi aventi lo stesso UID possono essere debuggati;
– 1 , solo il processo genitore può eseguire il debug;
– 2 , solo l’amministratore di sistema può utilizzare ptrace come richiesto dalla capability CAP_SYS_PTRACE ( man 7 capabilities );
– 3 , nessun processo può essere tracciato con ptrace.
I valori da assegnare sono funzione di ciò che si vuole proteggere: ad esempio, in un sistema con dati altamente sensibili non ha alcun senso mantenere il comportamento di default, pertanto si può impostare un valore pari a 3. Su un sistema desktop, a seconda degli usi, si possono impostare i valori 2, 1 o 0. Per cambiare il valore è sufficiente utilizzare, con le credenziali dell’amministratore, il comando:
echo "X" | tee /proc/sys/kernel/yama/ptrace_scope
oppure, per chi usa sudo :
echo "X" | sudo tee /proc/sys/kernel/yama/ptrace_scope
dove X è uno dei 4 valori di cui sopra.
Per concludere, si intuisce la complessità che si cela dietro un argomento che coinvolge apparentemente una singola voce: un mare di considerazioni solo per dire che se non serve (o se non torna utile) è il caso di disabilitare questa syscall.
Ti potrebbe interessare





4 mag 2017